Roger N. Shepard ,Toward a Universal Law of Generalization for Psychological Science.Science237,1317-1323(1987).DOI:10.1126/science.3629243
Starting from the seminal paper of Shepard (1987), I took a first glimpse of psychology as a quantitative science (like physics, which i love so much). The universality in the seemingly unpredictable, noisy behaviors is amazing.
Primacy of Generalization
Anything experienced by an individual is unlikely to recur in exactly the same form and context
- To make learning useful, one has to generalize.
- Each individual has an internal metric of similarity (exists at birth)
Generalization vs. failure of discrimination
Encountering an unfamiliar object requires the individual to infer the consequence
- Generalization is a cognitive act
- psychological vs. psychophysical
Early work
when Pavlov found that dogs would salivate not only at the sound of a bell or whistle that had preceded feeding but also at other sounds-and more so as they were chosen to be more similar to the original sound, for example, in pitch.
Empirical gradient of generalization: relate feature of response to some measure of difference
- strength, probability, speed etc.
Example. identification learning (Shepard, 1980)
- subjects learn a one-to-one association between $n$ stimuli and $n$ arbitrary verbal responses
- measure of generalization $g_{ij}$: the frequency with which any stimulus lead to response assigned to any other
Apparent noninvariance
To establish quantitative results, we have to choose a independent variable
- choosing physical measures of difference does not guarantee invariance
- the decrease in response has different patterns with various stimuli, sesory continuum, or species
- even exhibit nonmonotone increase: tones separated by an octave, hues at the opposite ends of the visible spectrum
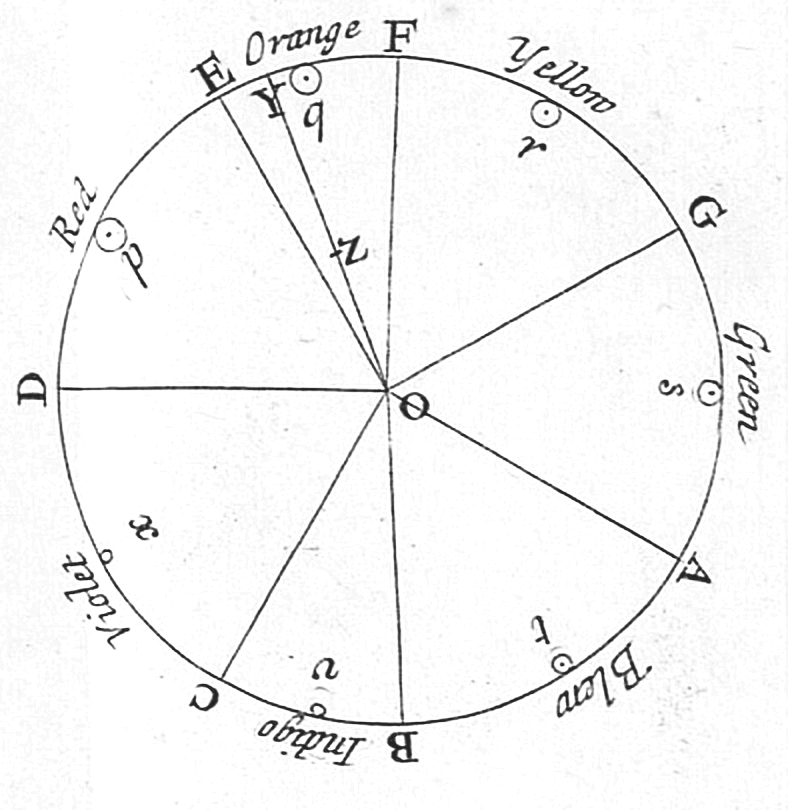
Newton’s_color_circle (Newton, 1704).
Establishing invariance in the psychological space
What is sometimes required is not more data or more refined data but a different conception of the problem.
Assume the invariant law of generalization is based on an appropriate psychological space Attribute the troublesome variations in the generalization gradients to variations in a psychophysical function (physical space $\rightarrow$ psychological space) A purely psychological function relates generalization to distance in the psychological space.
Is there an invariant monotonic function whose inverse will uniquely transform those data into numbers interpretable as distances in some appropriate metric space?
Goal: find a metric space (or, the inverse function) that explains the observed generalization data(Satisfying certain conditions like certain Cayley-Menger determinants https://en.wikipedia.org/wiki/Cayley%E2%80%93Menger_determinant)
- Uniqueness implied by geometric fact: rank order of distance can be a good approximation to the distances, when the number of points is not too small (relative to dimensionality)
- The function can be determined through nonmetric multidimensional scaling
- move $n$ points in a specified space, until the configuration minimizes some measure of departure (“stress”) from a monotonic relation between $g_{ij}$ and $d_{ij}$. \(g_{ij}=\bigg(\frac{p_{ij}\cdot p_{ji}}{p_{ii}\cdot p_{jj}}\bigg)^{1/2}\)
Empirical regularities
Invariance and (approximate) exponential decay
Invariance: in every case, the decrease of generalization with psychological distance is
- monotonic,
- generally concave upward, and
- more or less approximates a simple exponential decay function
MDS does not impose the form of function except for monotonicity.
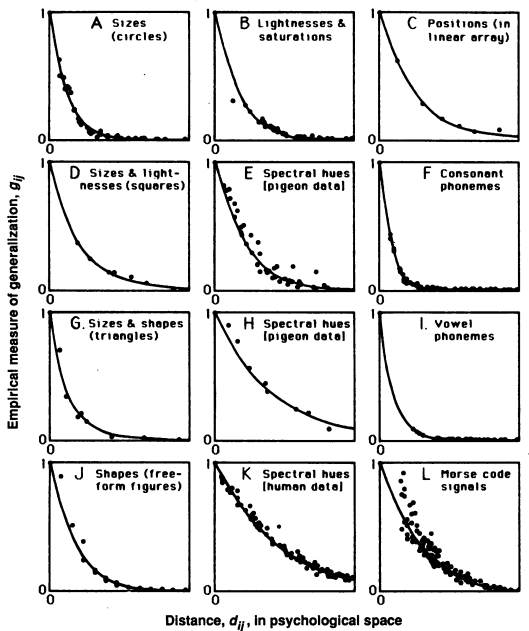
Gradients of generalization (Shepard, 1987).
Two distance metrics
When the psychological space has more than 1 dimension, data also provide evidence about the metric for unitary and analyzable stimuli
- integral attributes (lightness and saturation) : Euclidean metric
- separable attributes (size and orientation): ‘city-block’ metric They can be expressed as a Minkowski power metric \(d_{ij}=\bigg(\sum_{k=1}^K|x_{ik}-x_{jk}|^r\bigg)^{1/r}\)
A theory of generalization
Generalization is thus a cognitive act, not merely a failure of sensory discrimination.
Recognition as member of a “Natural kind”, corresponding to some consequential region $C$ in the psychological space.
Assumption: nature chose the consequential region at random
- all locations are equally probable
- size has density $p(s)$ with finite mean $\mu$ \(\int_0^\infty p(s)ds =1\,E[s]=\int_0^\infty s\cdot p(s)ds = \mu<\infty\)
- arbitrary shape that is centrally symmetric and has finite extension
Goal: estimate the conditional probability $P\big(x\in C\vert 0\in C)$
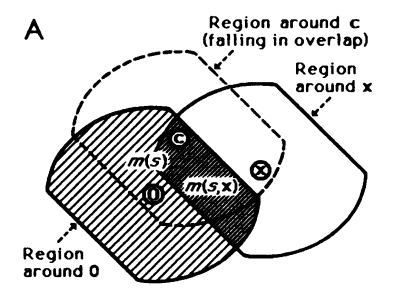
Consequential regions with fixed size (Shepard, 1987).
Given any size $s$, the probability of covering $x$ is the ratio of the volunetric measure. \(p(x\in C\vert s)=\frac{m(s,x)}{m(s)}\)
Marginalize out size to derive the conditional probability, denoted as $g(\cdot)$. Note that $p(\cdot)$ satisfies some conditions. \(g(x)=\int_0^\infty p(s)\frac{m(s,x)}{m(s)}ds\)
Exponential Law
Derivation with unidimensional case
A convex consequential region is an interval of a certain length \(m(s)=s\) \(m(s,x)=\left\{\begin{array}{ll} s-\vert x\vert,& s\geq \vert x\vert \\ 0, & s<\vert x\vert \end{array}\right.\)
Taking these into the previous expression, and taking derivatives lead to \(g''(d)=\frac{p(d)}{d}\)
Some simulation results with different size distribution
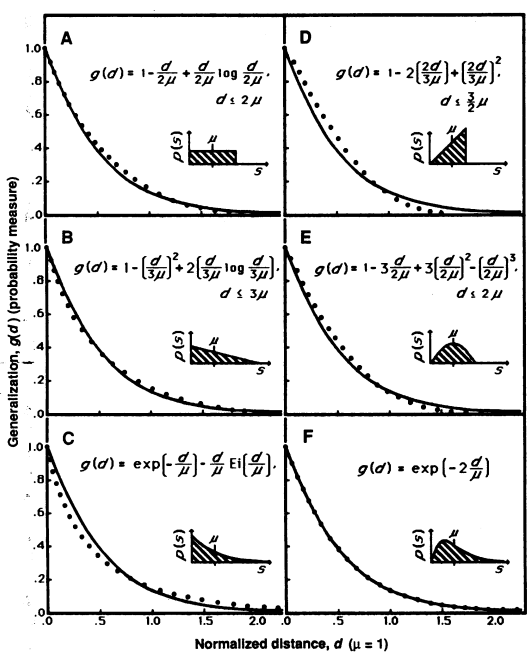
Generalization function and corresponding prior (Shepard, 1987).
- dependence on the prior is weak
- exponential law is exact under Erlang prior $p(s)=(\frac{2}{\mu})^{2}s\cdot \exp(\frac{-2}{\mu}s)$ \(g(d) = \exp\bigg(-2\frac{d}{\mu}\bigg)\)
- Erlang prior can be derived using Baysian update of prior assuming minimum knowledge (the first stimulus falls in the consequential region with probability proportional to its volumn $m(s)$)
\(p(s)=C\cdot m(s) \cdot q(s)\)
Derivation of two metrics
For multidimensional cases, different metrics can be considered as a result of different dependence relations between dimensions.
- For dimensions identified as independent variables in the world, extension of consequential region along these dimensions should not be correlated
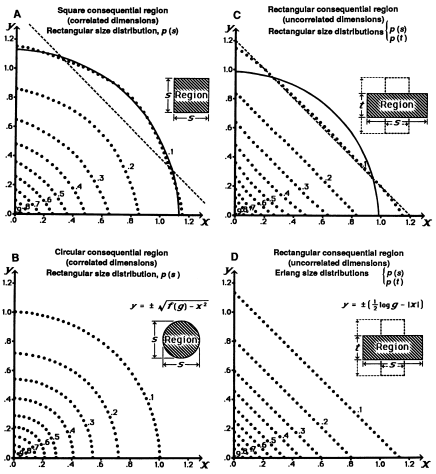
Equal generalization contours (Shepard, 1987).
Limitations
- When tested on highly similar stimuli, or in delayed test, “noise” will come into effect
- exponential decay $\rightarrow$ Gaussian (Shepard, 1987: fig.1 L)
- rhombic $\rightarrow$ elliptical curve of equal generalization for analyzable dimensions
- Effect of category learning; asymmetries of generalization
- Alternative explanations based on graded generalization form of consequential region
- Negative correlation of dimensions lead to $r<1$
- Time to discriminate reciprocally related to distance, not exponentially
